In recent years, the field of education has seen a growing interest in the use of data mining techniques to improve teaching, learning, and administrative decision-making. Data mining refers to the process of uncovering hidden patterns, correlations, and useful information from large volumes of data. It involves applying various computational and statistical methods to analyze datasets that are often too complex or vast for traditional aanalysis methods. In the context of education, it can be used to analyze student performance, predict academic success, identify at-risk students, personalize learning paths, and improve curriculum design. By using classification algorithms, educational institutions can categorize student data and outcomes. This allows educators to develop targeted interventions and support systems that address individual student needs. Clustering techniques can group students by performance or engagement levels, offering insights into effective teaching strategies for different learner groups. Histograms, regression and correlative analysis can reveal broader trends, such as the impact of teaching methods or the effectiveness of online learning tools. These insights help institutions make data-driven decisions that enhance the overall educational experience. The present study analyzes a dataset of student registration numbers and their respective grades across all subjects. Alphabetic grades were converted to numeric values to facilitate analysis. Histograms of all subjects' grades were generated, followed by linear regression and a correlation matrix to identify relationships between subjects. The outputs include scatter plots for linear regression results and a correlation matrix for subject relationships.
| Published in | American Journal of Education and Information Technology (Volume 9, Issue 1) |
| DOI | 10.11648/j.ajeit.20250901.18 |
| Page(s) | 57-68 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Linear Regression, Machine Learning, Academic Data Analysis, Correlation Matrix, Student Grade Analysis
SGPA | Semester Grade Point Average |
CGPA | Cumulative Grade Point Average |
DBMS FAI | Data Base Management Systems Fundamentals of Artificial Intelligence |
DM | Discrete Mathematics |
OOP | Object Oriented Programming |
OOPJ | Object Oriented Programming Through Java |
OS | Operating Systems |
| [1] | MacQueen, J. (1967). Some methods for classification and analysis of multivariate observations. Proc. Fifth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Statistics, University of California Press, Berkeley, 281-297. |
| [2] | Pedregosa et al. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, vol. 12, 2825-2830. |
| [3] | Imani, E., Luedemann, K., Scholnick-Hughes, S., Elelimy, E., & White, M. (2024). Investigating the Histogram Loss in Regression. |
| [4] | Minami, M., Lennert-Cody, C. E. Regression Tree and Clustering for Distributions. J. Agri. Bio. Env. Stats. (2024). |
| [5] | Zhang et al (2023). Improving the Accuracy and Internal Consistency of Regression-Based Clustering of High-Dimensional Datasets. Stat Appl Genet Mol Biol. 2023 Jul 25; 22(1). |
| [6] | Park, C., Choi, H., Delcher, C., Wang, Y., Yoon, Y. (2019). Convex Clustering Analysis for Histogram-Valued Data. Biometrics, 75(2), 603-612. |
| [7] | Benzel, S., & Stanescu, A. (2020). Histogram Methods for Unsupervised Clustering. Proceedings of the 2020 ACM Southeast Conference, Pages 248 - 251. |
| [8] | Hang, H., Huang, T., Cai, Y., Yang, H., & Lin, Z. (2021). Gradient Boosted Binary Histogram Ensemble for Large-scale Regression. |
| [9] | List, F. (2021). The Earth Mover's Pinball Loss: Quantiles for Histogram-Valued Regression. Proc. Machine Learning Res., Vol. 139, 6713-6735. |
| [10] | Hang et al (2021). Histogram Transform Ensembles for Large-scale Regression. J. Machine Learning Res., vol. 22, 1-87. |
| [11] | Hu, J., Chen, Y., Leng, C., & Tang, C. Y. (2023). Applied Regression Analysis of Correlations for Correlated Data. arXiv preprint arXiv: 2109.05861v2. |
APA Style
Atukuri, S. S., Busam, S., Khushalani, B. (2025). Exploring Academic Trends with Histograms, Linear Regression, and Correlation Matrix. American Journal of Education and Information Technology, 9(1), 57-68. https://doi.org/10.11648/j.ajeit.20250901.18
ACS Style
Atukuri, S. S.; Busam, S.; Khushalani, B. Exploring Academic Trends with Histograms, Linear Regression, and Correlation Matrix. Am. J. Educ. Inf. Technol. 2025, 9(1), 57-68. doi: 10.11648/j.ajeit.20250901.18
AMA Style
Atukuri SS, Busam S, Khushalani B. Exploring Academic Trends with Histograms, Linear Regression, and Correlation Matrix. Am J Educ Inf Technol. 2025;9(1):57-68. doi: 10.11648/j.ajeit.20250901.18
@article{10.11648/j.ajeit.20250901.18,
author = {Satya Sri Atukuri and Sruthi Busam and Bharat Khushalani},
title = {Exploring Academic Trends with Histograms, Linear Regression, and Correlation Matrix
},
journal = {American Journal of Education and Information Technology},
volume = {9},
number = {1},
pages = {57-68},
doi = {10.11648/j.ajeit.20250901.18},
url = {https://doi.org/10.11648/j.ajeit.20250901.18},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajeit.20250901.18},
abstract = {In recent years, the field of education has seen a growing interest in the use of data mining techniques to improve teaching, learning, and administrative decision-making. Data mining refers to the process of uncovering hidden patterns, correlations, and useful information from large volumes of data. It involves applying various computational and statistical methods to analyze datasets that are often too complex or vast for traditional aanalysis methods. In the context of education, it can be used to analyze student performance, predict academic success, identify at-risk students, personalize learning paths, and improve curriculum design. By using classification algorithms, educational institutions can categorize student data and outcomes. This allows educators to develop targeted interventions and support systems that address individual student needs. Clustering techniques can group students by performance or engagement levels, offering insights into effective teaching strategies for different learner groups. Histograms, regression and correlative analysis can reveal broader trends, such as the impact of teaching methods or the effectiveness of online learning tools. These insights help institutions make data-driven decisions that enhance the overall educational experience. The present study analyzes a dataset of student registration numbers and their respective grades across all subjects. Alphabetic grades were converted to numeric values to facilitate analysis. Histograms of all subjects' grades were generated, followed by linear regression and a correlation matrix to identify relationships between subjects. The outputs include scatter plots for linear regression results and a correlation matrix for subject relationships.
},
year = {2025}
}
TY - JOUR T1 - Exploring Academic Trends with Histograms, Linear Regression, and Correlation Matrix AU - Satya Sri Atukuri AU - Sruthi Busam AU - Bharat Khushalani Y1 - 2025/06/16 PY - 2025 N1 - https://doi.org/10.11648/j.ajeit.20250901.18 DO - 10.11648/j.ajeit.20250901.18 T2 - American Journal of Education and Information Technology JF - American Journal of Education and Information Technology JO - American Journal of Education and Information Technology SP - 57 EP - 68 PB - Science Publishing Group SN - 2994-712X UR - https://doi.org/10.11648/j.ajeit.20250901.18 AB - In recent years, the field of education has seen a growing interest in the use of data mining techniques to improve teaching, learning, and administrative decision-making. Data mining refers to the process of uncovering hidden patterns, correlations, and useful information from large volumes of data. It involves applying various computational and statistical methods to analyze datasets that are often too complex or vast for traditional aanalysis methods. In the context of education, it can be used to analyze student performance, predict academic success, identify at-risk students, personalize learning paths, and improve curriculum design. By using classification algorithms, educational institutions can categorize student data and outcomes. This allows educators to develop targeted interventions and support systems that address individual student needs. Clustering techniques can group students by performance or engagement levels, offering insights into effective teaching strategies for different learner groups. Histograms, regression and correlative analysis can reveal broader trends, such as the impact of teaching methods or the effectiveness of online learning tools. These insights help institutions make data-driven decisions that enhance the overall educational experience. The present study analyzes a dataset of student registration numbers and their respective grades across all subjects. Alphabetic grades were converted to numeric values to facilitate analysis. Histograms of all subjects' grades were generated, followed by linear regression and a correlation matrix to identify relationships between subjects. The outputs include scatter plots for linear regression results and a correlation matrix for subject relationships. VL - 9 IS - 1 ER -
Department of Artificial Intelligence, Shri Vishnu Engineering College for Women, Bhimavaram, India
Figure 1. Flowchart of Statistical Analysis.
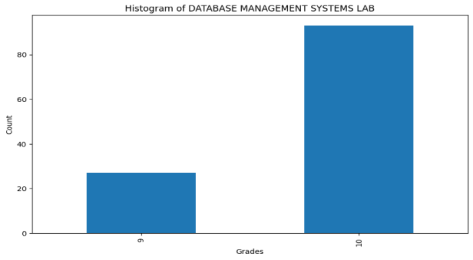
Figure 2. Histogram of Database Management Systems Lab.
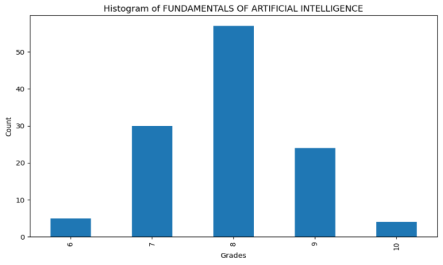
Figure 3. Histogram of Fundamentals of Artificial Intelligence.
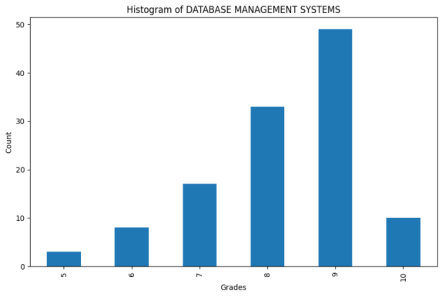
Figure 4. Histogram of Database Management Systems.
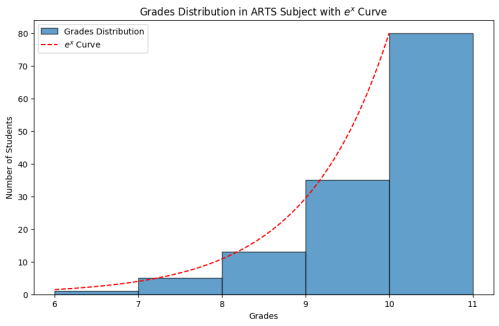
Figure 5. Exp Fit to ARTS grades.
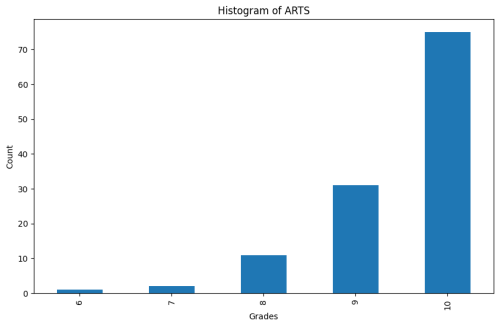
Figure 6. Histogram of Arts.
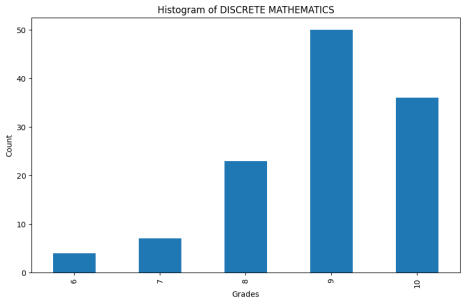
Figure 7. Histogram of Discrete Mathematics.
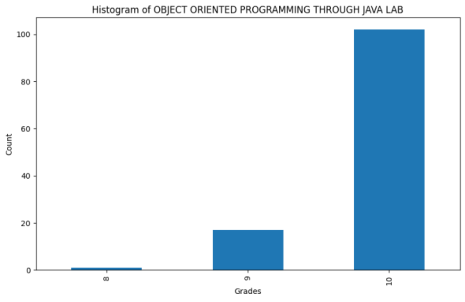
Figure 8. Histogram of OOPJ Lab.
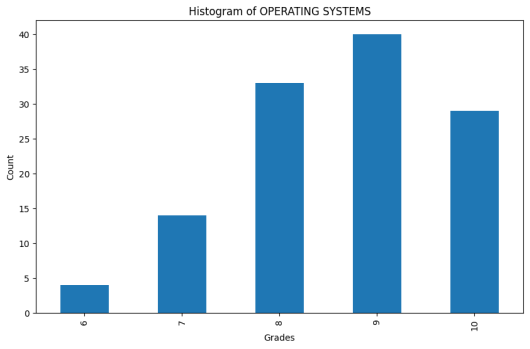
Figure 9. Histogram of Operating Systems.
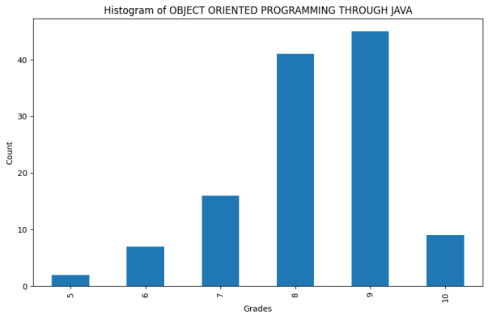
Figure 10. Histogram of OOPJ.
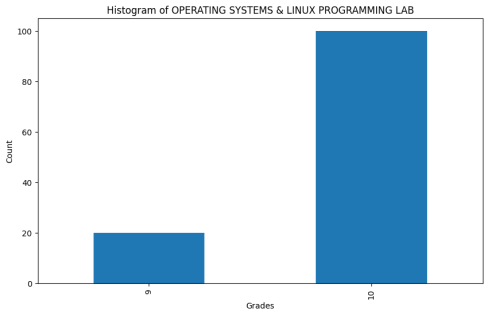
Figure 11. Histogram of OS & Linux Lab.
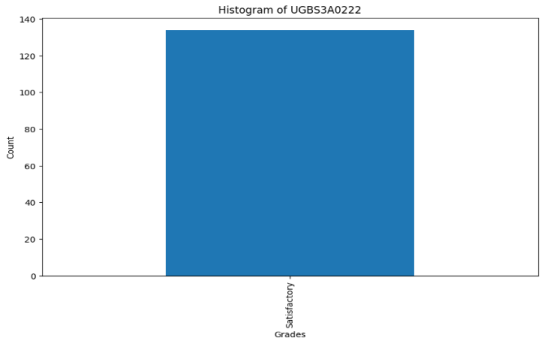
Figure 12. Histogram of Indian Constitution.
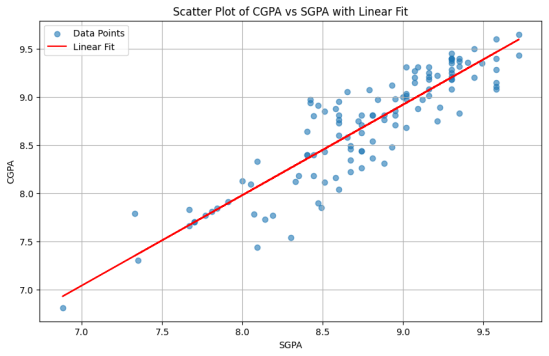
Figure 13. Scatter Plot of CGPA vs SGPA with Linear Fit.
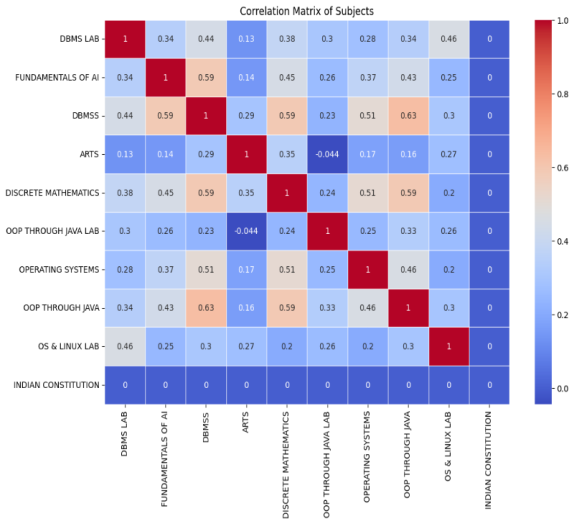
Figure 14. Correlation Matrix of subjects
Information

